下载VOC2012数据集,这里用的是镜像:镜像网址、Train/Validation dataset、test dataset 注意直接复制链接,浏览器不会接管下载,需要打开迅雷(最好有超级会员) 原本想复现的,师兄告诉我还是直接看v3好,故溜~ 参考链接:
- 目标检测:YOLOV1
- YOLOv1损失函数
- YOLO v1深入理解 可以看看评论区
- YOLO:实时快速目标检测 可以看看评论区
- 【目标检测】单阶段算法--YOLOv1详解
- 【论文解读】Yolo三部曲解读——Yolov1 可以看看评论区
#YOLOv1简介
相比于 R-CNN 系列的方法,YOLO提供了另外一种思路,将 Object Detection 的问题转化成一个 Regression 问题。给定输入图像,直接在图像的多个位置上回归出目标的bounding box以及其分类类别。YOLO是一个可以一次性预测多个Box位置和类别的卷积神经网络,能够实现端到端的目标检测和识别,其最大的优势就是速度快。YOLO没有选择滑动窗口(silding window)或提取proposal的方式训练网络,而是直接选用整图训练模型。这样做的好处在于可以更好的区分目标和背景区域,相比之下,采用proposal训练方式的Fast-R-CNN常常把背景区域误检为特定目标。但是YOLO目标区域定位误差更大(特别是小目标)。 优点:
First, YOLO is extremely fast. Since we frame detection as a regression problem we don't need a complex pipeline.(这里的回归问题不是特别理解。回归的目的是预测数值型的目标值,输入图像经过一次网络,便能得到图像中所有物体的位置和其所属类别及相应的置信概率) Second, YOLO reasons globally about the image when making predictions. Unlike sliding window and region proposal-based techniques, YOLO sees the entire image. Third, YOLO learns generalizable representations of objects. When trained on natural images and tested on art- work, YOLO outperforms top detection methods like DPM and R-CNN by a wide margin.
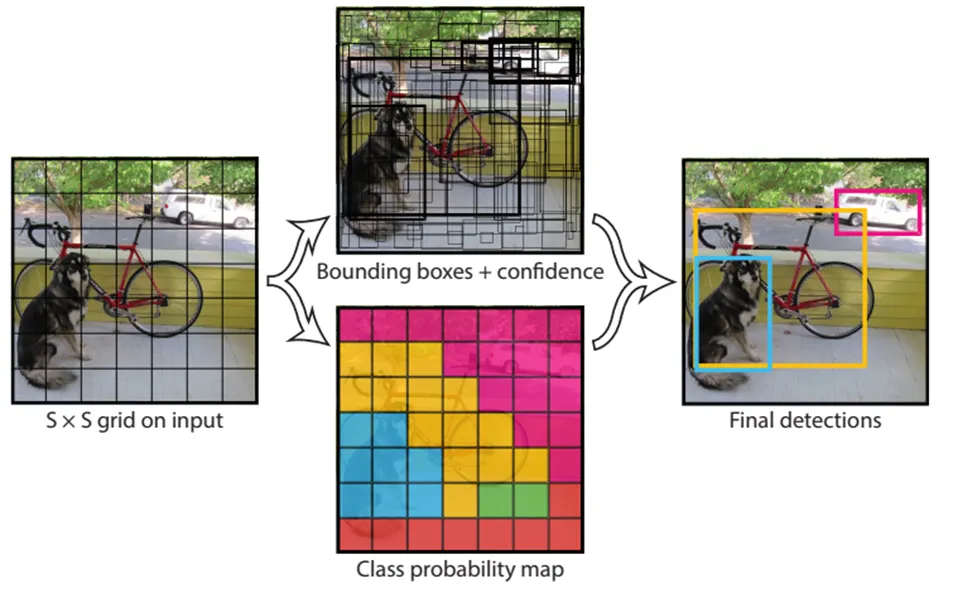 Our system models detection as a regression problem. It divides the image into an S × S grid and for each grid cell predicts B bounding boxes, confidence for those boxes, and C class probabilities. These predictions are encoded as an S × S × (B ∗ 5 + C) tensor.
Our system models detection as a regression problem. It divides the image into an S × S grid and for each grid cell predicts B bounding boxes, confidence for those boxes, and C class probabilities. These predictions are encoded as an S × S × (B ∗ 5 + C) tensor.
实现方案:Link,大致下面这个区域,因为都是原文摘抄,所以不全部复制了。
1)结构 去掉候选区这个步骤以后,YOLO的结构非常简单,就是单纯的卷积、池化最后加了两层全连接。单看网络结构的话,和普通的CNN对象分类网络几乎没有本质的区别,最大的差异是最后输出层用线性函数做激活函数,因为需要预测bounding box的位置(数值型),而不仅仅是对象的概率。所以粗略来说,YOLO的整个结构就是输入图片经过神经网络的变换得到一个输出的张量,如下图所示。
- 另外文中将图片resize为448*448,一些图片会发生很大的变形,所以尽量训练数据和测试数据分布保持一致。
- YOLO并没有预先设置2个bounding box的大小和形状,也没有对每个bounding box分别输出一个对象的预测。它的意思仅仅是对一个对象预测出2个bounding box,选择预测得相对比较准的那个。这里采用2个bounding box,有点不完全算监督算法,而是像进化算法。如果是监督算法,我们需要事先根据样本就能给出一个正确的bounding box作为回归的目标。但YOLO的2个bounding box事先并不知道会在什么位置,只有经过前向计算,网络会输出2个bounding box,这两个bounding box与样本中对象实际的bounding box计算IOU。这时才能确定,IOU值大的那个bounding box,作为负责预测该对象的bounding box。 训练开始阶段,网络预测的bounding box可能都是乱来的,但总是选择IOU相对好一些的那个,随着训练的进行,每个bounding box会逐渐擅长对某些情况的预测(可能是对象大小、宽高比、不同类型的对象等)。所以,这是一种进化或者非监督学习的思想。
- responsible: We assign one predictor to be “responsible” for predicting an object based on which prediction has the highest current IOU with the ground truth. This leads to specialization between the bounding box predictors. Each predictor gets better at predicting certain sizes, aspect ratios, or classes of object, improving overall recall.
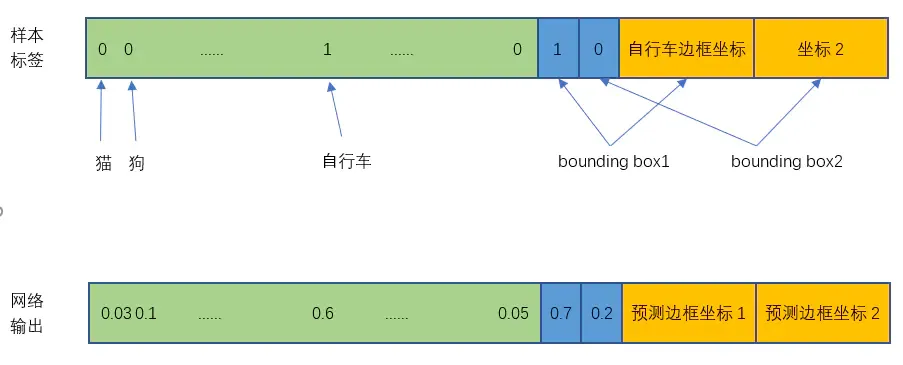
- 设网格数量为 SS,每个网格产生B个边框,数据集包含C个不同的对象。这时,输出的长度为:$(C+B(4+1))SS$
#论文关键部分翻译:Unified Detection
We unify the separate components of object detection into a single neural network. Our network uses features from the entire image to predict each bounding box. It also predicts all bounding boxes across all classes for an image simultaneously. This means our network reasons globally about the full image and all the objects in the image. The YOLO design enables end-to-end training and realtime speeds while maintaining high average precision.
我们将目标检测的不同组件整合到一个神经网络中。我们的网络使用整张图片的特征来预测每一个边界框。它还同时预测图像的所有类中的每一个边界框。这表示我们的网络全局推理整张图片和图片上的所有对象。YOLO的设计可以进行端到端训练和达到实时的速度并且保持相对高的准确度。 Our system divides the input image into an_ S _× S grid. If the center of an object falls into a grid cell, that grid cell is responsible for detecting that object.
我们的系统将输入图片分成S×S的网格。如果一个对象的中心点落在某个网格内,则这个网格负责预测这个对象。(计算出该Object的bounding box的中心位置,这个中心位置落在哪个grid,该grid对应的输出向量中该对象的类别概率是1(该gird负责预测该对象),所有其它grid对该Object的预测概率设为0(不负责预测该对象)参考网址。另外最多能检测出S*S个物体,如果每个物体的中心点在每个网格内) Each grid cell predicts B bounding boxes and confidence scores for those boxes. These confidence scores reflect how confident the model is that the box contains an object and also how accurate it thinks the box is that it predicts. Formally we define confidence as $\operatorname{Pr}(\text { Object }) * \mathrm{IOU}_{\text {pred }}^{\text {truth }}$. If no object exists in that cell, the confidence scores should be zero. Otherwise we want the confidence score to equal the intersection over union (IOU) between the predicted box and the ground truth.
每个网格预测B个bboxes和这些boxes的置信度。其中置信度反映了模型对这个box包含对象的信任度和模型认为这个box预测有无对象的准确度。我们定义置信度为有无对象的预测值(非0即1)* truth box和pred box的交并比。如果没有object在网格内,则置信度应为0. 否则我们将置信度等于预测框和真实框的交并比。
Each bounding box consists of 5 predictions: x, y, w, h,_ _and confidence. The (x, y) coordinates represent the center of the box relative to the bounds of the grid cell. The width and height are predicted relative to the whole image. Finally the confidence prediction represents the IOU between the predicted box and any ground truth box.
每个bbox包含5个预测值:x, y, w, h and 置信度。(x, y)表示bbox相对于网格单元格边界的中心坐标。预测的高宽相对于整张图片的高宽。最后,置信度预测表示pred and truth 的交并比
Each grid cell also predicts C conditional class probabilities, $\operatorname{Pr}\left(\text { Class }{i} \mid \text { Object }\right)$. These probabilities are conditioned on the grid cell containing an object. We only predict one set of class probabilities per grid cell, regardless of the number of boxes B_.
每个网格也预测C个条件类型概率,即存在对象时,属于某类别的概率。这些概率以网格内包含对象为条件。我们仅预测每个网格的一系列的类别概率,不管bbox的个数。(相当于每个网格只输出一个类型概率,而不会输出bbox的类别概率,bbox输出置信度) At test time we multiply the conditional class probabilities and the individual box confidence predictions, $\begin{equation*} \operatorname{Pr}\left(\text { Class }{i} \mid \text { Object }\right) * \operatorname{Pr}(\text { Object }) * \mathrm{IOU}{\text {pred }}^{\text {truth }}=\operatorname{Pr}\left(\text { Class }{i}\right) * \mathrm{IOU}{\text {pred }}^{\text {truth }} \end{equation*}$ which gives us class-specific confidence scores for each box. These scores encode both the probability of that class appearing in the box and how well the predicted box fits the object.
在测试阶段我们将conditional class probabilities乘上每个bbox的置信度预测值,公式中i指的是类别个数,所以有$\operatorname{Pr}\left(\text { Class }{1}\right) * \mathrm{IOU}{\text {pred }}^{\text {truth }}、 \operatorname{Pr}\left(\text { Class }{2}\right) * \mathrm{IOU}{\text {pred }}^{\text {truth }}...\operatorname{Pr}\left(\text { Class }{i}\right) * \mathrm{IOU}{\text {pred }}^{\text {truth }}$,这样子使我们得到关于每个bbox的特定类的置信度。这些值也反映了bounding box是否含有Object和bounding box坐标的准确度。
最后在PASCAL VOC中 S=7,B=2,C=20,最终输出为7×7×30的标量(30=(4+1)*2+20, 4是xywh,1是置信度,2是bbox个数,20类别数)
#损失函数
图片来源:Link
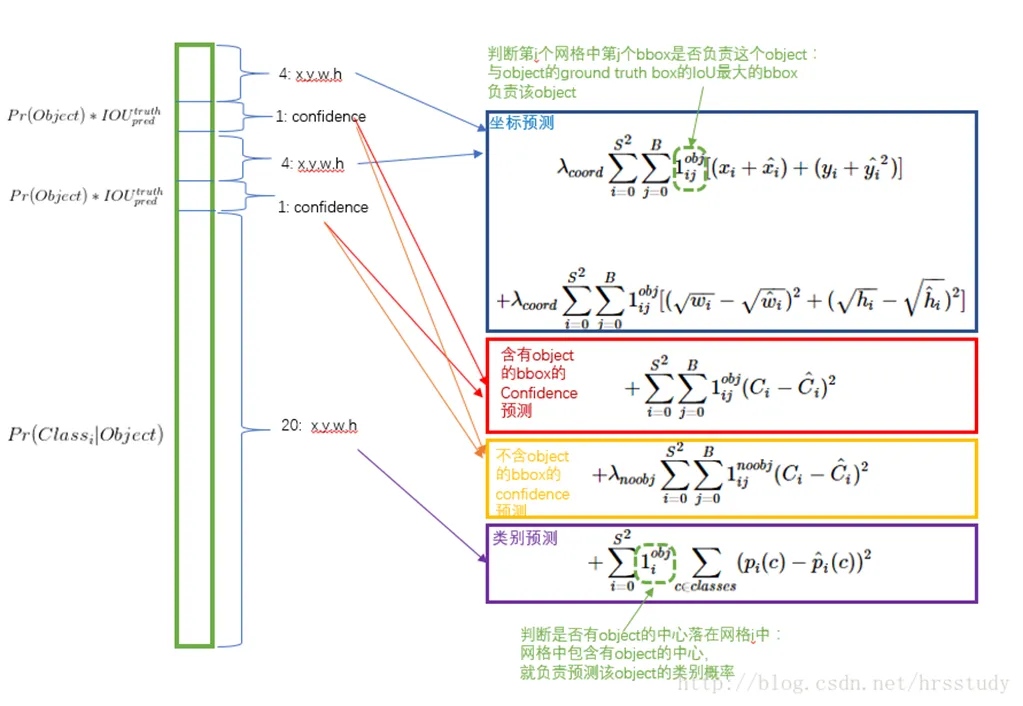
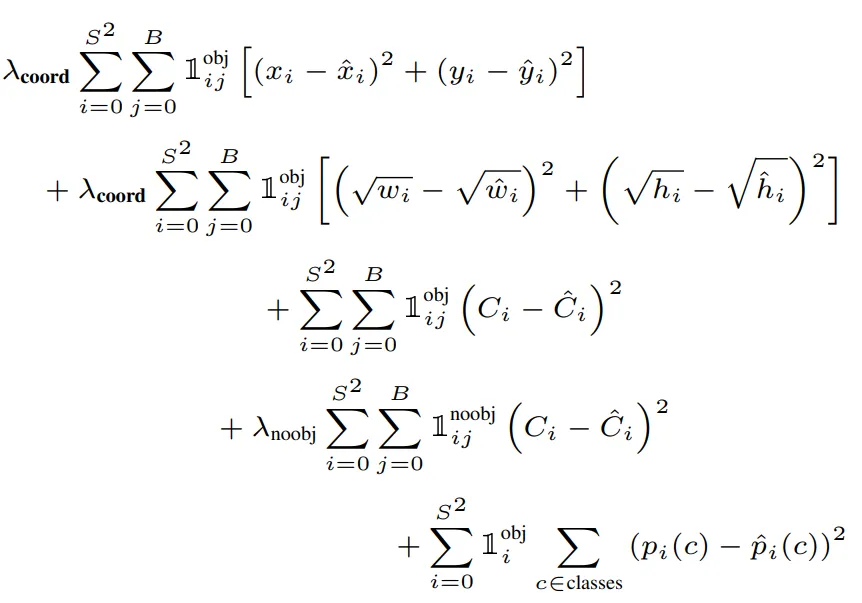 $1_{ij}^{obj}$表示第i个网格中的第j个bbox有对象
$1_{ij}^{noobj}$表示第i个网格中的第j个bbox无对象
$1_{ij}^{obj}$表示第i个网格中的第j个bbox有对象
$1_{ij}^{noobj}$表示第i个网格中的第j个bbox无对象
- 第一行是预测框的中心,只计算含有物体时的bbox(IOU大的那个)损失值,因为$1_{ij}^{obj}$无对象其值为0。
- 第二行是预测框的高宽,与第一行不同的是wh取了根号,如果不取根号,损失函数则偏向于调整大尺寸的预测框,因为修改小尺寸的话对loss有较大的影响,如h=1000,error=25;h=100,error=25的情况下,应该小框的误差要严重,因此loss要加大,但是不取平方根则1000-975 = 100-75, Sum-squared error also equally weights errors in large boxes and small boxes,加了根号则sqrt(1000)-sqrt(975) ≈0.4 < sqrt(100)-sqrt(75) ≈1.33,此时小框误差就体现出来了。平方根函数的上升趋势是递减的,越来越平缓(评论最后一页:Link)。
- 第三行是预测框包含对象时的置信度
- 第四行是预测框不包含对象时的置信度,这里解释挺多的,我也分辨不过来哪个是对的,故全复制过来了。
- 第4行是不存在对象的bounding box的置信度误差。因为不存在对象的bounding box应该老老实实的说"我这里没有对象",也就是输出尽量低的置信度。如果它不恰当的输出较高的置信度,会与真正"负责"该对象预测的那个bounding box产生混淆。其实就像对象分类一样,正确的对象概率最好是1,所有其它对象的概率最好是0。
- 如果一些栅格中没有object(一幅图中这种栅格很多),那么就会将这些栅格中的bounding box的confidence 置为0,相比于较少的有object的栅格,这些不包含物体的栅格对梯度更新的贡献会远大于包含物体的栅格对梯度更新的贡献,这会导致网络不稳定甚至发散。
- 不包含obj的置信度损失就是包含两部分,一部分是包含obj的grid cell中的两个BBox中不负责预测的那个BBox,另外一部分是不包含obj的grid cell的bbox。损失计算时,负责预测物体的bbox的便签值就是IOU的值,不负责预测物体的bbox的标签值就是0(包含上述所描述的两部分),预测值就是网络直接输出出来的,计算时就是两者相减后取平方。
- 后续我的理解,可以看到第二幅图,因为每个网格都会输出预测值,即使bbox的C较小,$(C_i-C^{hat}_i)=(0-0.2)^2482$也会变得很大(48是包含对象时49-1,然后*bbox个数,其实还要+1,因为IOU小的那个也被淘汰了),所以要乘个小数
- 第五行是网格包含物体时的物体类别概率。
#训练过程和推理interference过程
#train
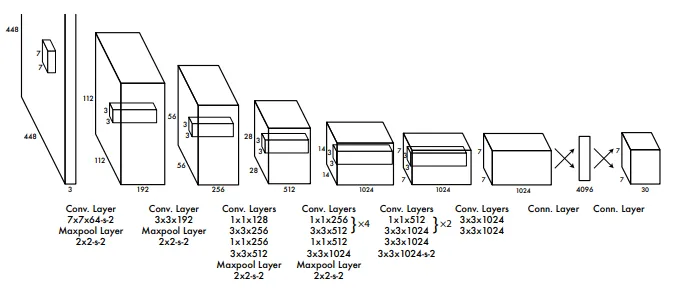 作者采用ImageNet 1000-class 数据集来预训练卷积层。预训练阶段,采用上图网络中的前20卷积层(包括池化层),外加average-pooling 层和全连接层。然后,将模型转换为检测模型使用DarkNet架构并用于interference阶段。作者向预训练模型中加入了4个卷积层和两层全连接层,提高了模型输入分辨率(224×224->448×448)。最后一层预测类别概率和bounding box坐标值。bounding box的宽和高通过输入图像宽和高归一化到0-1区间。最后一层采用linear activation,其它层使用 leaky rectified linear。作者采用sum-squared error为目标函数来优化,增加bounding box loss权重,减少置信度权重,实验中,设定为$λ_{coord} =5$,$λ_{noobj} = .5$。
作者还采用了dropout和 data augmentation来预防过拟合。dropout值为0.5;data augmentation包括:random scaling,translation,adjust exposure和saturation。
作者采用ImageNet 1000-class 数据集来预训练卷积层。预训练阶段,采用上图网络中的前20卷积层(包括池化层),外加average-pooling 层和全连接层。然后,将模型转换为检测模型使用DarkNet架构并用于interference阶段。作者向预训练模型中加入了4个卷积层和两层全连接层,提高了模型输入分辨率(224×224->448×448)。最后一层预测类别概率和bounding box坐标值。bounding box的宽和高通过输入图像宽和高归一化到0-1区间。最后一层采用linear activation,其它层使用 leaky rectified linear。作者采用sum-squared error为目标函数来优化,增加bounding box loss权重,减少置信度权重,实验中,设定为$λ_{coord} =5$,$λ_{noobj} = .5$。
作者还采用了dropout和 data augmentation来预防过拟合。dropout值为0.5;data augmentation包括:random scaling,translation,adjust exposure和saturation。
#inference
训练好的YOLO网络,输入一张图片,将输出一个 7730 的张量(tensor)来表示图片中所有网格包含的对象(概率)以及该对象可能的2个位置(bounding box)和置信度。 因为一些大物体或者靠近多个网格的边界的物体会产生多个预测框,YOLO采用NMS(Non-maximal suppression,非极大值抑制)算法来减少。
#limitation
- YOLO的每一个网格只预测两个boxes,一种类别。这导致模型对相邻目标预测准确率下降。因此,YOLO对成队列的目标(如 一群鸟)识别准确率较低。
- YOLO是从数据中学习预测bounding boxes,因此,对新的或者不常见角度的目标无法识别。
- YOLO的loss函数对small bounding boxes和large bounding boxes的error平等对待,影响了模型识别准确率。因为对于小的bounding boxes,small error影响更大。主要识别错误来源是不正确的定位框。
#错误分析
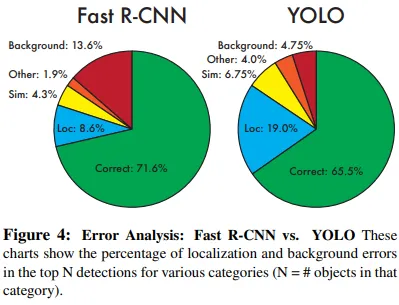 预测结果包括以下几类:
正确:类别正确,IOU>0.5
定位:类别正确,0.1<IOU<0.5
类似:类别相似,IOU>0.1
其它:类别错误,IOU>0.1
背景:IOU<0.1
预测结果包括以下几类:
正确:类别正确,IOU>0.5
定位:类别正确,0.1<IOU<0.5
类似:类别相似,IOU>0.1
其它:类别错误,IOU>0.1
背景:IOU<0.1
#文中的小技巧
- 回归offset代替直接回归坐标
We parametrize the bounding box x and y coordinates to be offsets of a particular grid cell location so they are also bounded between 0 and 1
(x, y)不直接回归中心点坐标数值,而是回归相对于格点左上角坐标的位移值。 例如,第一个格点中物体坐标为 (2.3, 3.6) ,另一个格点中的物体坐标为(4.2, 4.6),这四个数值让神经网络暴力回归,有一定难度。所以这里的offset是指,既然格点已知,那么物体中心点的坐标一定在格点正方形里,相对于格点左上角的位移值一定在区间[0, 1)中。让神经网络去预测 (0.3, 0.6) 与 (0.2, 0.6) 会更加容易,在使用时,加上格点左上角坐标(2, 3)、(4, 4)即可。
#问题
为什么一个网格只检测一个目标:实时目标检测