source insight
#C++ 概括
C++优点
- 强大的封装能力:既有开发工程能力,又保留高性能
- 高性能:运行快,快并且占用资源少是C++的追求
- 低功耗:适合嵌入式
C++缺点:
#C++ 基础语法
#编程语言层次
- 机器语言,汇编语言
- 编译型语言 C++,C
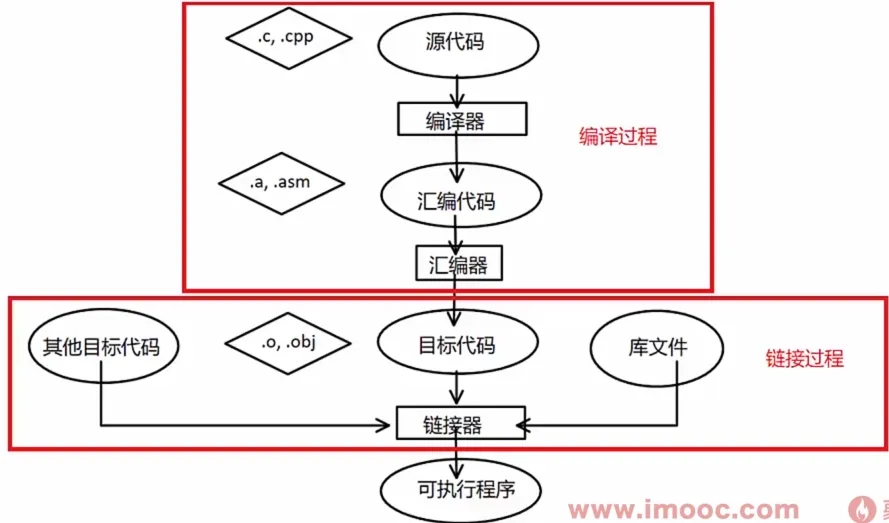
- 解释型语言 Basic Python Java
- 脚本语言 bash csh
#数据类型
 疑问,为什么64位三个字节对齐
疑问,为什么64位三个字节对齐
定义常量的方法:
- #define: #define PI 3.14159
- #define MA(x) x*(x-1)
- MA(1 + (a + b)) = 1+(a+b)*(1+(a+b)-1)
- const:const double PI = 3.14159 (推荐)
整数常量前缀:0x 十六进制、0 八进制、0b
整数常量后缀:u(unsigned)、l(long)、可组合使用,大小写任意
字符常量:单引号括起来,用L(必须大写)表示宽字符常量
#运算符与表达式
#关系运算符
A == B 其值为bool类型 而直接判断为1为int类型,注意空间大小
#杂项运算符
,:顺序执行一系列运算后,取最后一个表达式的值(int o = a,b,c)
正数原补反码一致
负数
- 反码是原码除符号位取反,补码=反码+1,反码=补码-1
- 二进制to补码:$B 2 T_{w}(\vec{x}) \stackrel{.}{=} x_{w-1} 2^{w-1}+\sum_{i=0}^{w-2} x_{i} 2^{i}$
一文搞清二进制补码
#字节序
一个字在内存中如何以byte存放
- 大端法:大多数IBM机器、网络传输,正序存放 8f ff ff ff
- 小端法:Intel兼容机,逆序存放,但字节内正序 ff ff ff 8f
#位运算
#C陷阱和C++改进
#char语法陷阱
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| #include <iostream>
void main()
{
char c1 = 'yes'; // 截断:1.保留第一个字符 2.保留第二个字符
std::cout << c1 << std::endl;
// char* 32bi机器占4位,64占8位,为了搜索整个地址空间
const char* s1 = "/"; // ==> '/''\0'
// const char* s2 = '/'; 字符常量->char* 类型不匹配
const char* s2 = &c1;
// C++ 改进, string 在namespace std中
std::string s1(3, 'yes'); // s
std::string s2("yes"); // yes
}
|
#数组退化陷阱
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| #include <iostream>
#include <vector>
// double average1(int arr[10], int len) {
double average1(int* arr, int len) { // C:数组退化成指针
// 传递char数组可以通过计算到'\0'的长度来不借助len
double result = 0;
// 形参arr[10]变为int指针,arr[0]为int类型 => len = 4/4 = 1
// int len = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i < len; i++){
result += arr[i];
}
return result / len;
}
// C++ 改进
double average3(std::vector<int> &v) {
double result = 0;
std::vector<int>::iterator it = v.begin();
// auto it = v.begin();
for (; it != v.end(); ++it){
result += *it;
}
return result / v.size();
}
double average2DV(std::vector<std::vector<int>>& vv) {
double result = 0.0;
unsigned int size = 0;
for (unsigned int i = 0; i < vv.size(); ++i) {
for (unsigned int j = 0; j < vv[i].size(); ++j) {
result += vv[i][j];
size += 1;
std::cout << (vv[i][j])+" "; // +' '自动变为int
}
std::cout << std::endl;
}
return result / size;
}
void main()
{
int arr[10] = { 10, 20, 30, 40,50 };
int len = sizeof(arr) / sizeof(arr[0]);
// std::cout << average1(arr, len) << std::endl;
std::vector<int> vt{ 12,3,4,5,6,5 };
std::cout << average3(vt) << std::endl;
std::vector< std::vector<int>> vv{8,std::vector<int>(12, 3) };
std::cout << average2DV(vv);
}
|
#移位问题
问题:
逻辑右移还是算数右移 -> 右移只对无符号数
移位操作位数的限制 -> 移位数大于0, 小于位数
- C中需要考虑整数移位上下文情况(有无符号数,类型占字节数)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| #include <iostream>
#include <bitset>
using namespace std;
int main() {
char a1 = 0x63; // 0110 0011
a1 = (a1 >> 4); // 0000 0110 逻辑右移
printf("0x%x\n", a1);
char a2 = 0x95; // 1001 0101
a2 = (a2 >> 4); // 1111 1001 算法右移
printf("0x%x\n", a2);
unsigned char a3 = 0x95; // 1001 0101 C建议先转无符号再右移
a3 = (a3 >> 4); // 0000 1001 逻辑右移
printf("0x%x\n", a3);
//const unsigned char priv = 0xff;
//const unsigned char P_BACKUP = (1 << 7);
//const unsigned char P_ADMIN = (1 << 8); // 超过char位数-> =0
//// 判断用户权限的技巧
//if (priv & P_BACKUP) cout << "BACKUP" << endl;
// C++ 改进
bitset<10> priv = 0xff;
bitset<10> P_BACKUP = (1 << 6);
bitset<10> P_ADMIN = (1 << 7); // 超过char位数-> =0
// 判断用户权限的技巧
if ((priv & P_BACKUP) == P_BACKUP) cout << "BACKUP" << endl;
}
|
#类型转换问题
C缺陷:隐式转换问题(sizeof(unsigned long long) 跟int比较,int转换为unsigned int)、double除法问题
C++改进:static_cast、const_cast、dynamic_cast、reinterpret_cast,建议尽量少使用转换,多长啊
#溢出问题
C整数固定为int所占字节,溢出会有问题
C++:使用boost库的cpp_int
#字符串问题
C 以'\0'结尾,遇到即停止,忽视其后面的值,运行效率低,只能以'\0'表示字符串结束
C++:string库(仍保留'\0')、redis库(用多个结构体优化存储空间,并用len防止'\0'问题)
字符串比较 >< 比较的是首地址大小
#头文件顺序
- 系统的头文件要放在最前面;
- 其次是语言相关的;
- 然后比较古老的第三方库头文件;
- 比较新的第三方库头文件;
- 最后才是自定义的头文件。
#基础容器
#数组(差一错误)
- off-by-one error
- 解决思路:先考虑简单特例,然后外推结果;仔细计算边界
- 判断范围时采取左闭右开,使其相减为元素个数 for (int i =0; i<10; i++)
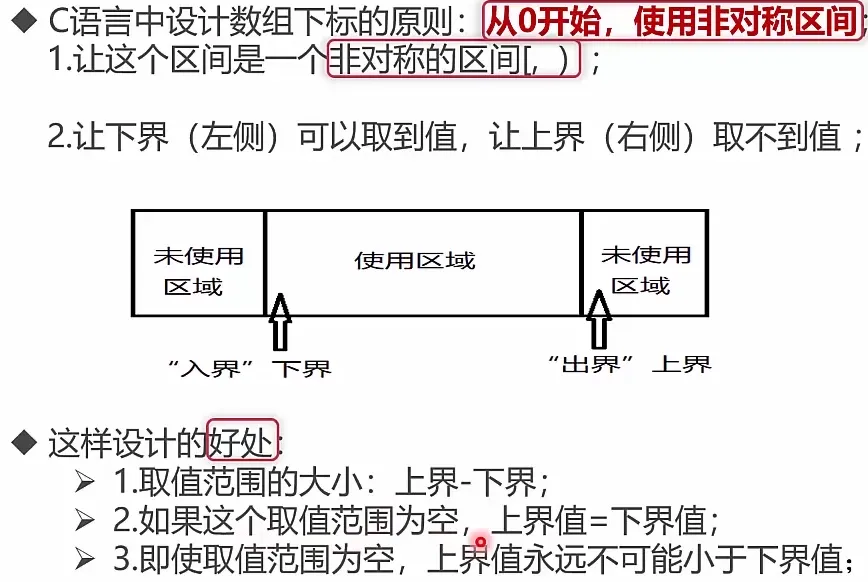
数组的下标访问和指针访问方式效率分析
二维数组访问时的原则:尽可能满足空间局部性
- 在一个小的时间窗口内,访问的变量地址越接近越好,执行速度越快
- 一般将最长的循环放最内层,最短的放最外层,以减少CPU跨切循环层的次数
#vector
#字符串
表示Unicode字符集:
- UTF-8:1byte表示字符,兼容ASCII码;特点是存储效率高,变长(不方便内部随机访问),无字节序问题(作为外部编码,供其他平台使用Linux)
- 微软平台下又细分为UTF-8-BOM,二进制首位为EF BB BF,可能在其他平台有问题,可以删去首位来适配
- UTF-16:分为UTF-16BD(big endian)、UTF-16LD(little endian);特点是定长(方便内部随机访问),有字节序问题。
- BD文件的二进制首位为FE FF、LD为FF FE(正序)
- UTF-32:分为UTF-32BD、UTF-32LD;特点同上
字符串的指针表示方法
- char[] 和 char*的区别:
- char[] 地址不可变 其内的值可变
- char* 地址可变,其内的值取决于所指存储区域是否可变
#常用函数安全问题
- strlen、strcpy等没有对边界检查容易导致缓冲区溢出,修改一些值
- 修改为strlen_s、strcpy_s等函数
- 调试时加入_CRT_SECURE_NO_WARNINGS
#String 和 char*
char* / char[] :
- strcpy_s 拷贝
- strlen 字符串长度
- strcat 拼接
- strcmp 比较ASCII码
String:
- =
- str.size() \ str.length()
- +=
- ==
- str.capacity() 容量,自动扩容
相比来说String 性能不是特别好
#C++指针
指针占用空间由操作系统位数决定,因为要指向所有地址
#左值与右值
左值为编译器为其单独分配一块存储空间,可以取其地址。可以放在任意侧赋值运算符
右值为数据本身,不能取其地址。只能放在赋值运算符右侧。
- 没有标识符(变量名),不可以&取地址的表达式,一般称为“临时对象”。
#指针分类
#数组指针
array of pointers:
- int* a[4],包含四个指针的a数组
- 输出结果:*(a[3])
a pointer to an array:
- int (*a)[4],指向一个包含四个值的数组,其中4要与数组个数匹配
- 输出结果:(*a)[3] -> array[3] <=> *(array+3) <=> array[3]
- 同样的
- int *a = array
- 输出结果:*(a+3)
#const指针
const修饰的部分为不可修改内容,其修饰的部分看左侧最近的部分,如果左侧没有,则看右侧
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| #include "stdafx.h"
#include <iostream>
using namespace std;
unsigned int MAX_LEN = 11;
int main()
{
char strHelloworld[] = { "helloworld" };
// 与strHelloWorld变量共享内存
char const * pStr1 = "helloworld"; // const char* 不能修改指向的char内容
// 导致此处赋值后使得pStr1指向的空间可被修改,不能只读
char* const pStr2 = strHelloworld; // 不能修改指针值
char const* const pStr3 = "helloworld"; // const char* const 不能修改内容和指针
pStr1 = strHelloworld;
//pStr2 = strHelloworld; // pStr2不可改
//pStr3 = strHelloworld; // pStr3不可改
unsigned int len = strnlen_s(pStr2, MAX_LEN);
cout << len << endl;
for (unsigned int index = 0; index < len; ++index)
{
//pStr1[index] += 1; // pStr1里的值不可改
pStr2[index] += 1;
//pStr3[index] += 1; // pStr3里的值不可改
}
return 0;
}
|
#多级指针
1
2
3
4
5
| int a = 12;
int* b = &a;
int** c = &b;
// *有从右向左的结合性,不清楚优先级就用括号
*(*c) = *(b) = a = 12
|
#野指针
未初始化的指针
- 可能导致无法定位错误
- 用指针进行间接访问时,确保访问的值已被初始化赋值
NULL指针
- 初始化指针,使其无地址
- 对指针进行间接引用时,最好判断指针是否NULL
- 不用,没有初始化,超出范围时,使其NULL
野指针分类
- 指针变量没有初始化
- 已经释放不用的指针没有置NULL
- 指针操作超越了变量的作用范围,指向不确定的空间
#指针基本操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| char ch = 'a';
char* cp = &ch;
// ++,--操作符
char* cp2 = ++cp;
char* cp3 = cp++;
char* cp4 = --cp;
char* cp5 = cp--;
// ++ 左值
//++cp2 = 97;
//cp2++ = 97;
// *++, ++*
*++cp2 = 98; // cp2地址加1后赋值
char ch3 = *++cp2; // cp2地址加1后将引用的值给左值
*cp2++ = 98; // 将cp2指向的空间赋值后地址加1
char ch4 = *cp2++; // 将cp引用的值给左值后地址加1
// ++++, ----操作符等
int a = 1, b = 2, c, d;
//c = a++b; // error
c = a++ + b; // 贪心法
//d = a++++b; // error
char ch5 = ++*++cp; // 1.先cp地址+1, 2.得到其引用的值, 3.值+1, 4.赋给左值
|
delete and delete[]、删除指针后并不会置为nullptr
对于像 int/char/long/int*/struct 等等简单数据类型,由于对象没有 destructor,所以用 delete 和 delete [] 是一样的!但是如果是C++ 对象数组就不同了!
#内存分配
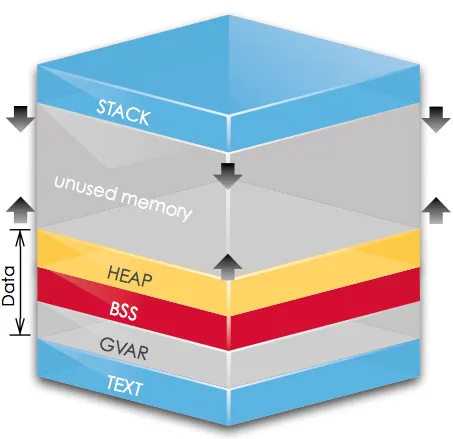
- stack:由程序分配地址
- heap:由程序员分配地址 new/delete
- heap和bss之间是常量区
- bss:未初始化区
- gvap:初始化区
- text:代码、函数。。。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| #include <string>
int a = 0; // (GVAR)全局初始化区
int* p1; // (bss)全局未初始化区
int main() // (text)代码区
{
int b=1; // (stack)栈区变量 32位/64位地址递减/递增 栈区初始化值cc
char s[] = "abc"; // (stack)栈区变量
int*p2=NULL; // (stack)栈区变量
char *p3 = "123456"; // 123456\0在常量区, p3在(stack)栈区
static int c = 0; // (GVAR)全局(静态)初始化区
p1 = new int(10); // (heap)堆区变量 32位/64位地址递增 堆区初始化值cd
p2 = new int(20); // (heap)堆区变量
char* p4 = new char[7]; // (heap)堆区变量
strcpy_s(p4, 7, "123456"); // (text)代码区
return 0; // (text)代码区
}
|
#C++智能指针
auto_ptr:
- C++17 废弃
- 会自动删除指针以及指向的对象,会产生所有权转移现象
unique_ptr:
- 专属所有权,unique_ptr管理的内存,只能被一个指针持有,不支持复制
- 该指针禁止复制,因此用是std::move()语句进行所有权转移
- 离开作用域后,自动释放指针和数据
share_ptr / weak_ptr:
- 通过一个引用计数共享对象,当计数位0时,调用析构函数
- 会带来额外的存储开 销
- weak_ptr用于防止循环引用
一个特殊的指针,可以看作是变量的别名,但会同时修改变量的值,且不可更换指针对象
有了指针为什么还要引用?为了支持函数运算符重载
有了引用为什么还用指针?为了兼容C
函数传参说明:
- 对内置基础类型(如int,double)而言,函数传递时pass by value更高效,直接传值而不是指针/引用
- 对面向对象中的自定义类型而言,传递时pass by reference to const更高效,因为防止传递大数据而使用地址占用空间更小,const为了防止无意的修改
#C++基础语法
if将命中率高(更容易判true/false)的条件放首位,使得判断条件更快
与switch比较
使用场景:
- switch只支持常量值固定相等的分支判断
- if可以判断区间
- switch是if的特集
性能比较:
- 分支较少时,差别不大;分支多时,switch更快,因为是汇编是查表的形式
- if多分支的开始几个分支效果高,之后效率递减;因为汇编下需要不断判断再跳转
- switch所有case速度几乎一样,查表形式
- 枚举值不可以做左值
- 非枚举变量不可以赋值给枚举变量,除非强转;枚举可以赋值给非枚举
#Union / Struct
共用体
- 所有变量占用最大空间的变量的存储空间
- 大字节最后赋值会覆盖小字节内容
- 赋值从内存最右边赋值
缺省对齐原则
- char 任何地址
- short 偶数地址
- int 4的整数倍地址
- double 8的整数倍地址
- 32位内存里一行四字节,变量占用空间不足会扩充到最大占用空间变量
- 32位,char+int=8;8+double=16
- 32位,char[5]+int = 16;16+double=24
- 修改默认编译选项:
- visual C++:#pragma pack(n)
- g++:attribute(aligned(n))、attribute(packed)
do while更快 while 次之 for最慢,但实际开发不重视速度的话,无所谓
#函数重载
- 看debug运行过程
- 看反汇编的地址
- 找到debug/.obj文件,搜搜函数名,复制【?函数名@@xx】,搜索【undname】,cmd命令 【undname 复制值】
用函数指针来确定某个函数:
- 一般形式:数据类型(*指针变量名)(参数表)
- bool ProcessNum(int i, int j, int(*p)(int a, int b)) // 回调函数
#命名空间
namespace 空间名{ ... }
注意使用using namespace std,会引入所有空间内方法,可能会导致方法名冲突
- 建议引入特定空间内方法名,using namespace std::cout;
- 或直接指定该方法是该空间内,std::cout <<
#函数体heck过程
函数调用方式:_cdecl(/Gd) (C/C++→高级→调用约定)
| 低地址 | esp |
|---|
| ... | ... |
| (地址向上递减) | ebx (栈向上增长) |
| 高地址 | ebp |
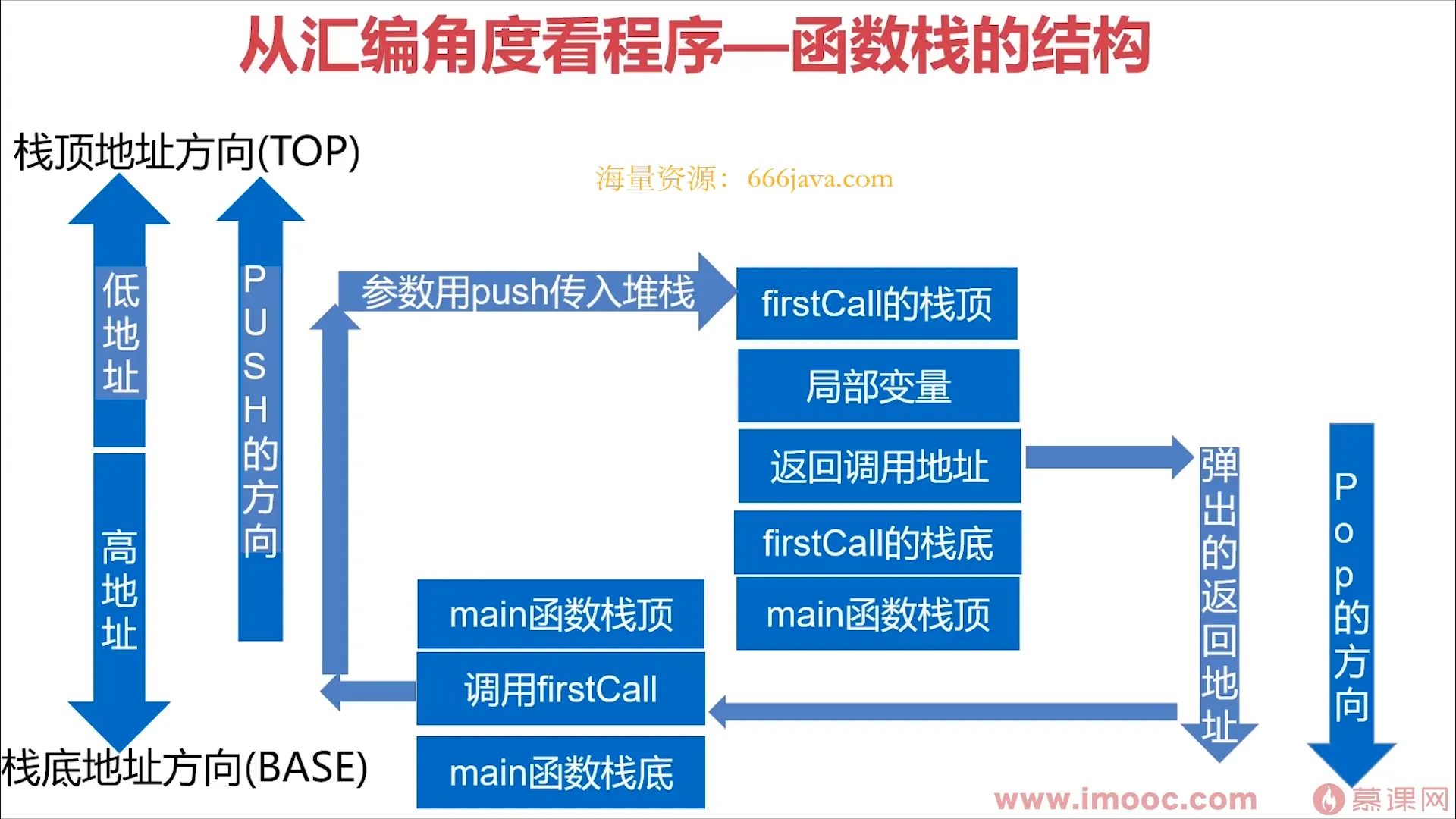
传参时为什么默认参数要在最右边,因为汇编时先push最右边的值(不同调用方式有差别)
#内联函数inline
用空间换时间,复杂函数可能不会内联
四个基本法则:
- 基准情形:无需递归就能解出
- 不断递进:每次递归都靠近基准情形
- 设计法则:假设所有递归都能运行
- 合成效益法则:不做重复性工作
缺陷:
优化:
- 尾递归:所有递归形式的调用都出现在函数的末尾
- 使用循环替代
- 使用动态规划,空间换时间
#C++高级语法
C++使用struct、class定义类
struct默认成员权限是public、class默认private
#运算符重载
#临时对象
1
2
3
4
5
6
7
8
9
10
11
12
13
| // main调用
Complex C; C = a + b;
// 对象函数
Complex Complex::operator+ (const Complex& c) const
{
// 创建临时对象,并且会触发拷贝构造,浪费时间
Complex tmp;
tmp._real = _real + c._real;
tmp._image = _image + c._image;
return tmp;
// 直接返回创建对象
//return Complex(_real + c._real, _image + c._image);
}
|
临时对象的处理:
1
2
3
4
5
6
7
8
9
10
| // 1. 自建拷贝构造
Complex::Complex(const Complex& c)
{
_real = c._real;
_image = c._image;
cout << "Complex::Complex(const Complex& c)" << endl;
}
// 2. 定义时赋值(下次都定义时赋值)
Complex C = a + b; // 并且重载符直接return对象 而不是创建临时对象
// 此外可节省调用默认构造函数
|
#前置后置++
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| Complex& Complex::operator++ () // 前置++ 效率快
{
_real++;
_image++;
return *this;
}
Complex Complex::operator++ (int) // 后置++
{
//Complex tmp(*this);
//_real++;
//_image++;
//return tmp;
return Complex(_real++, _image++);
}
|
#标准输入输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| // .h
#include <iostream>
using std::cout;
using std::cin;
friend ostream& operator<<(ostream& os, const Complex &x);
friend istream& operator>>(istream& is, Complex &x);
// .cpp
ostream& operator<<(ostream& os, const Complex &x)
{
os << "real value is " << x._real << " image value is " << x._image;
return os;
}
istream& operator >> (istream& is, Complex &x)
{
is >> x._real >> x._image;
return is;
}
// 防止缓冲区遗留数据:
cin.ignore(numeric_limits<std::streamsize>::max(), '\n'); // 清空缓冲区脏数据
|
使用转义字符。使用 "<" 代替 “<” , 使用 ">" 代替 ">"。防止识别为html
#文件操作
文件的打开方式:
- ios::in 打开文件进行读(ifstream默认)
- ios::out 打开文件进行写(ofstream默认ios::out | ios::trunc)
- ios::ate 打开一个已有输入/输出的文件并查找到文件尾
- ios::app 打开文件如没有则创建文件,在尾部添加数据
- ios::nocreate 如果文件不存在,则打开操作失败
- ios::trunc 如文件存在,清楚文件原有内容
- ios::binary 以二进制打开
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| static const int bufferLen = 2048;
bool CopyFile(const string& src, const string& dst)
{
// 打开源文件和目标文件
// 源文件以二进制读的方式打开
// 目标文件以二进制写的方式打开
ifstream in(src.c_str(), ios::binary);
ofstream out(dst.c_str(), ios::binary);
// 判断文件打开是否成功,失败返回false
if (!in || !out)
{
return false;
}
// 从源文件中读取数据,写到目标文件中
// 通过读取源文件的EOF来判断读写是否结束
char temp[bufferLen];
while (!in.eof())
{
in.read(temp, bufferLen);
streamsize count = in.gcount();
out.write(temp, count);
}
// 关闭源文件和目标文件
in.close();
out.close();
return true;
}
|
#头文件重定义
1
2
3
4
5
6
7
8
9
| #ifndef _SOMEFILE_H_ // 任意专属名称
#define _SOMEFILE_H_
...
#endif //末尾
// 使用宏防止同一个文件被多次包含;
// 优点:可移植性好;缺点:无法防止宏名重复,难以排错
#pragma once
// 使用编译器防止
// 优点:防止宏重复;缺点:可移植性不好
|
#深拷贝 浅拷贝 move操作
浅拷贝:只拷贝指针地址,C++默认拷贝构造函数与赋值运算符重载都是浅拷贝;节省空间,但会引发多次释放。
深拷贝:重新分配堆内存,拷贝指针指向内容。浪费空间,但不会多次释放。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| String::String(const String &other){ // 拷贝构造函数
m_data = new char[strlen(other.m_data) + 1];
if (m_data != NULL)
strcpy(m_data, other.m_data);
else
exit(-1);
}
String& String::operator= (const String &other){ // 赋值函数
if (this == &other)
return *this;
// 释放原有的内容
delete[ ] m_data;
// 重新分配资源并赋值
m_data = new char[strlen(other.m_data) + 1];
if (m_data != NULL)
strcpy(m_data, other.m_data);
else
exit(-1);
return *this;
}
|
兼有两者优点:1. 计数,2. move操作
move:当旧指针不用时,资源让渡给新指针,即move操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| // 调用
String s2A(std::move(s1));
String::String(String&& other){ // 移动构造函数 &&右值引用
if (other.m_data != NULL){
// 资源让渡
m_data = other.m_data;
other.m_data = NULL;
}
}
// 调用
String s3A;
s3A = std::move(s2A);
String& String::operator=(String&& rhs)noexcept{ // 移动赋值运算符
if(this != &rhs)
{
delete[] m_data;
m_data = rhs.m_data;
rhs.m_data = NULL;
}
return *this;
}
|
// 面对变化,尽可能少修改原有的逻辑,要扩充逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| class Shape // 抽象类
{
public:
virtual double Area() const = 0;// 子类方法实现不一致加上virtual 不创建对象用=0
virtual void Show() = 0;
void SetColor(int color) { _color = color; }
void Display()
{
cout << Area() << endl;
}
private:
int _color;
};
class Square: public Shape
{
public:
Square(double len) :_len(len) { }
void Show() { cout << "Square" << endl; }
double Area() const
{
return _len*_len;
}
private:
double _len;
};
|
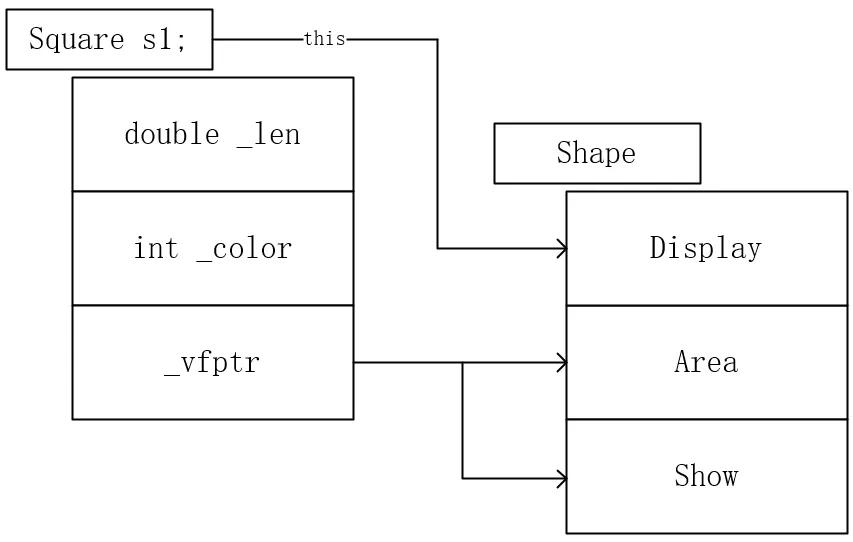
所以sizeof(s1) = 16 = 8+4+4
#三大特性
封装、继承、多态

#编程思想
#单例模式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| // .h
class Singleton
{
public:
static const Singleton* getInstance();
static void DoSomething()
{
cout << "Do Something" << endl;
}
// 将构造和析构函数私有化,防止外部访问
private:
Singleton();
~Singleton();
static Singleton* This; // 使用静态变量帮助解决资源的分配和释放
};
// .cpp
#include "Singleton.h"
// 无法解析的外部符号 "private: static class Singleton * Singleton::This"
Singleton* Singleton::This = nullptr; // = new Singleton();
const Singleton* Singleton::getInstance()
{
if (!This)
{
This = new Singleton;
}
return This;
}
Singleton::Singleton(){}
Singleton::~Singleton(){}
|
懒汉模式和恶汉模式 null/new
#观察者模式
观察者关注被观察者动态,如果被观察者动态更新,则通知观察者做出相应处理。
#void*、nullptr
1
2
3
4
5
6
7
8
9
10
11
| // C
#define NULL((void*)0)
// C++
#define NULL
#ifdef _cplusplus
#define NULL 0
#else
#define NULL((void*)0)
#endif
#endif
// vc++即使定义指针为NULL,也会转成nullptr即void*
|
#C++的类型转换
const_cast:用于将const转换成非const
reinterpret_cast:重新解释类型,两者内存空间必须一致,不检查指向的内容和其指针类型
static_cast:基本类型转换,有继承关系的类对象和类指针转换,由程序员来检查是否错误,没有动态转换的类型安全检查开销
dynamic_cast:只用于包含虚函数的类,用于多态中,向上向下转换时,错误则置空,增加检查开销
#适配器模式
将一个类的接口或实现类转化成客户要求的另一个新功能接口,实现复用。
- 采用多重继承的方式
- 实现新功能接口
- 创建适配器类继承新功能接口和旧功能实现类或接口
- 在类中实现新功能
- 创建接口对象指针 指向新实现类,调用方法
- 采用组合方式
- 实现新功能接口
- 创建适配器继承接口,并在类内创建旧类对象
- 新功能中使用旧类对象调用旧方法
- 创建接口对象指针 指向新实现类,调用方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| class LegacyRectangle // 旧
{
public:
LegacyRectangle(double x1) {
_x1 = x1;
}
void LegacyDraw() {
cout << "LegacyRectangle:: LegacyDraw()" << _x1 << endl;
}
private:
double _x1;
};
class Rectangle // 新接口
{
public:
virtual void Draw(string str) = 0; //虚函数用于继承给子类
};
// 第一种适配的方式:使用多重继承
class RectangleAdapter: public Rectangle, public LegacyRectangle
{
public:
RectangleAdapter(double w) : LegacyRectangle(w) {
cout << "RectangleAdapter" << endl;
}
virtual void Draw(string str) {
cout << "RectangleAdapter::Draw()" << endl;
LegacyDraw();
}
};
// 组合方式的Adapter
class RectangleAdapter2 :public Rectangle
{
public:
RectangleAdapter2(double w) :_lRect(w) {
cout << "RectangleAdapter2" << endl;
}
virtual void Draw(string str)
{
cout << "RectangleAdapter2::Draw()" << endl;
_lRect.LegacyDraw();
}
private:
LegacyRectangle _lRect;
};
// main
RectangleAdapter ra(x, y, w, h);
Rectangle* pR = &ra;
|
#泛型编程
::方法名() 调用自己的函数
泛型编程是一种静态期多态,通过编译器生成最直接的代码。
1
2
3
| template<Class T1, class T2>
int max(T1 a, T2 b){
return static_cast<int>(a > b ? a:b);
|
#进阶编程
#STL标准库
- 序列式容器
- 可排序,vector、list、deque,而stack、queue、priority_queue是容器适配器
- 关联式容器
- 每个数据元素由键值对组成,set,multiset,map,multimap
- note:迭代器删除时,注意删除操作使得迭代器失效,iter = .erase(iter) or iter++
#函数指针、仿函数模板
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| // C++仿函数模板
template<class T>
struct SortTF
{
inline bool operator() (T const& a, T const& b) const
{
return a < b;
}
};
template<class T>
struct DisplayTF
{
inline void operator() (T const& a) const
{
cout << a << " ";
}
};
// C++仿函数模板
int arr4[] = { 4, 3, 2, 1, 7 };
sort(arr4, arr4 + 5, SortF());
for_each(arr4, arr4 + 5, DisplayF());
cout << endl;
|
#自定义迭代器
必须提供iterator_traits的五种特性,才能和STL共同使用:
1
2
3
4
5
6
7
8
9
10
| // 分别是迭代器类型、元素类型、距离类型、指针类型与reference类型
//template<class Iterator>
//struct iterator_traits
//{
// typedef typename Iterator::difference_type difference_type;
// typedef typename Iterator::value_type value_type;
// typedef typename Iterator::pointer pointer;
// typedef typename Iterator::reference reference;
// typedef typename Iterator::iterator_category iterator_category;
//};
|
#容器适配器
- stack:先进后出,底层是deque
- queue:先进先出,底层deque
- priority_queue:进行堆排序,底层是vector或deque
#空间适配器
#boost库
#多线程
加锁应尽可能粒度最小化
#Linux编程
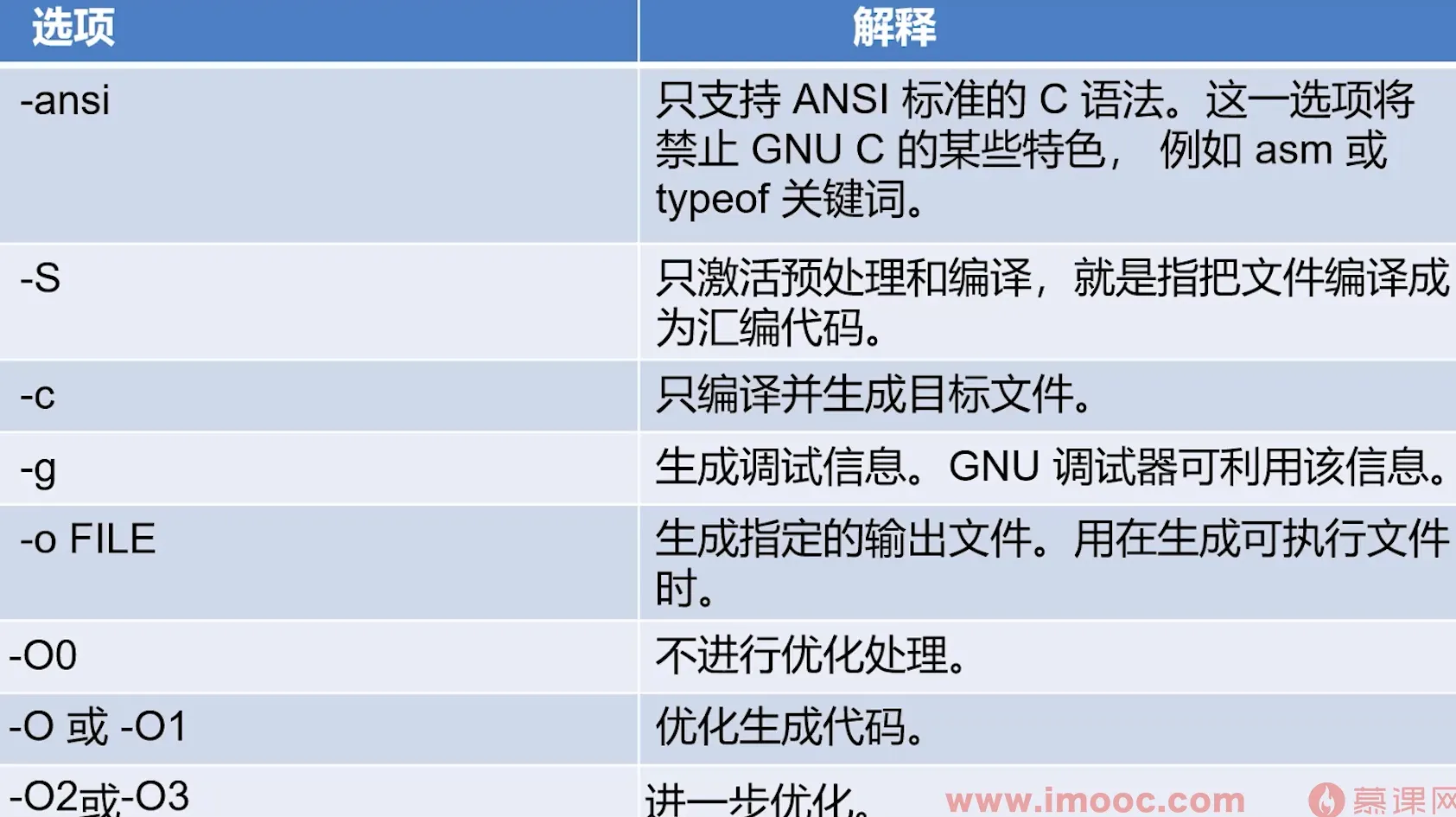
#makefile
https://www.gnu.org/software/make/manual/
1
2
3
4
5
6
7
8
| // 目标: 依赖
// 命令 (前面有个tab)
main: test.o main.o
g++ test.o main.o -o main
test.o: test.cpp
g++ -c test.cpp -o test.o
main.o: main.cpp
g++ -c main.cpp -o main.o
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| // 变量定义:变量 = 字符串
// 变量使用:$(变量名)
TARGET = main
OBJS = test.o main.o
$(TARGET): $(OBJS)
g++ $(OBJS) -o $(TARGET)
test.o: test.cpp
main.o: main.cpp
.PHONY: clean
clean:
rm $(TARGET) $(OBJS)
// 不生成目标文件的命令最好使用.PHONY 使其为假想目标
// 扩展用法 /usr/local/bin/系统环境变量(查看echo $path)
install:
cp ./main /usr/local/bin/mainTest
uninstall:
rm /usr/local/bin/mainTest
|

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| TARGET = main // main 和 .o的区别 试试main.o or test
OBJS = test.o
LIB = libtest.so
CXXFLAGS = -c -fPIC
$(TARGET): $(LIB) main.o
$(CXX) main.o -o $(TARGET) -L. -ltest -Wl,-rpath ./
$(LIB):$(OBJS)
$(CXX) -shared $(OBJS) -o $(LIB)
$(OBJS):test.cpp
$(CXX) $(CXXFLAGS) test.cpp -o $(OBJS)
main.o: main.cpp
$(CXX) $(CXXFLAGS) main.cpp -o main.o
.PHONY: clean
clean:
rm $(TARGET) $(OBJS)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| TARGET = main
OBJS = test.o
LIB = libtest.so
CXXFLAGS = -c -fPIC
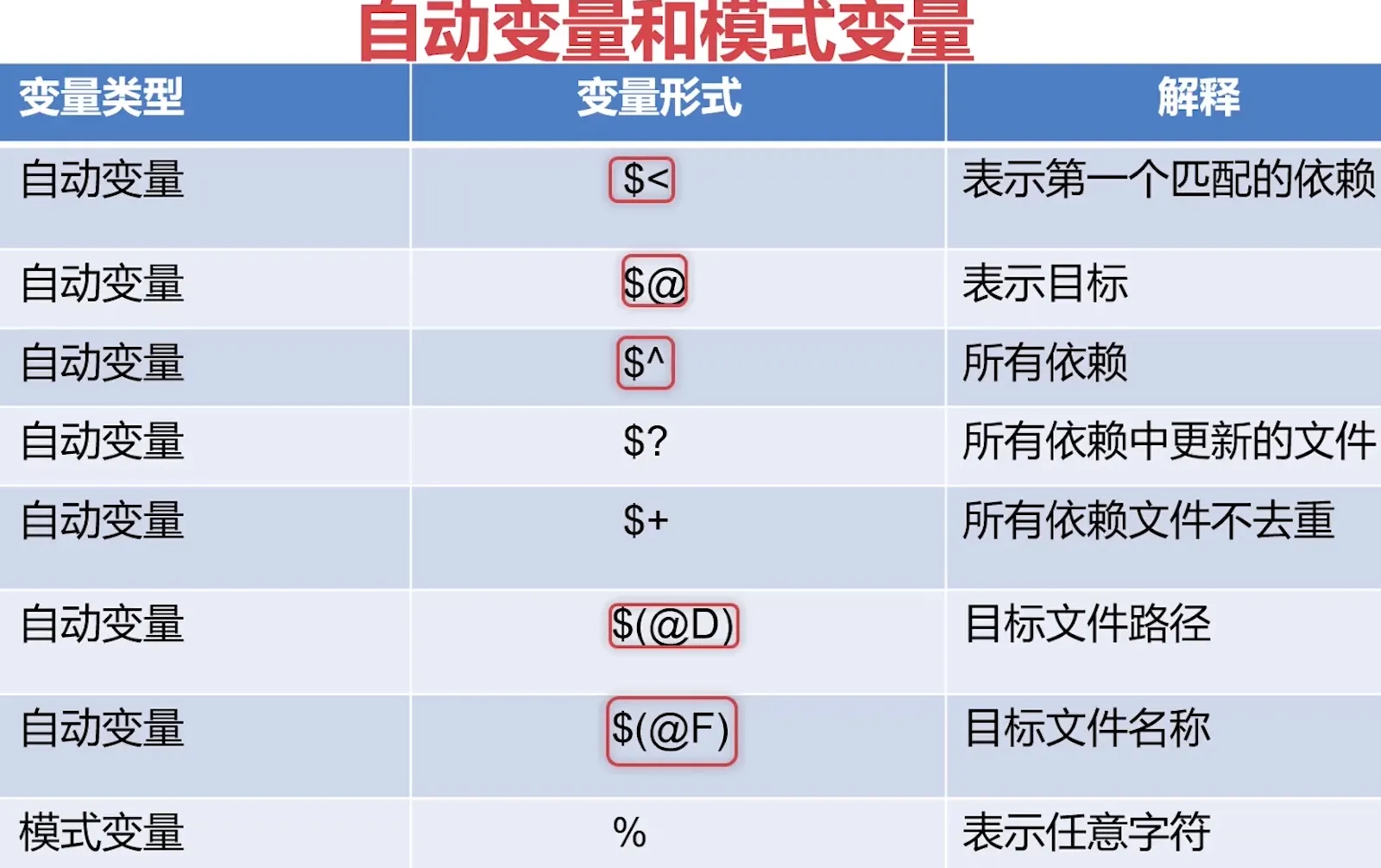
LDFLAGS = -L. -ltest -Wl,-rpath $(@D)
$(TARGET): main.o $(LIB) // 第一个依赖main.o
$(CXX) $< -o $@ $(LDFLAGS)
$(LIB):$(OBJS)
$(CXX) -shared $^ -o $@
%.o:%.cpp
$(CXX) $(CXXFLAGS) $^ -o $@
.PHONY: clean
clean:
$(RM) $(TARGET) $(OBJS) $(LIB) main.o
|
#项目实战
在qt项目下新建bat文件,输入qmake -tp vc 项目名.pro 即可生成sln文件
#汇编语言